
ChatGPT Creates a New MCP Session for Every Tool Call. Claude Doesn't.
We caught something weird.
We’re building mcpr, an open-source proxy for MCP servers. Our cloud dashboard tracks every MCP request at the protocol level — including session lifecycle. Initialize calls, tool invocations, session IDs, latencies. Everything.
While monitoring a production MCP server that serves both ChatGPT and Claude simultaneously, we noticed a pattern that made us do a double-take:
ChatGPT: 2 tool calls. 2 separate sessions. Claude: 2 tool calls. 1 session.
Same server. Same tools. Same protocol. Completely different behavior.
Let us show you.
The raw data
Section titled “The raw data”Here’s exactly what our dashboard recorded for a simple interaction where the AI calls two tools back-to-back.
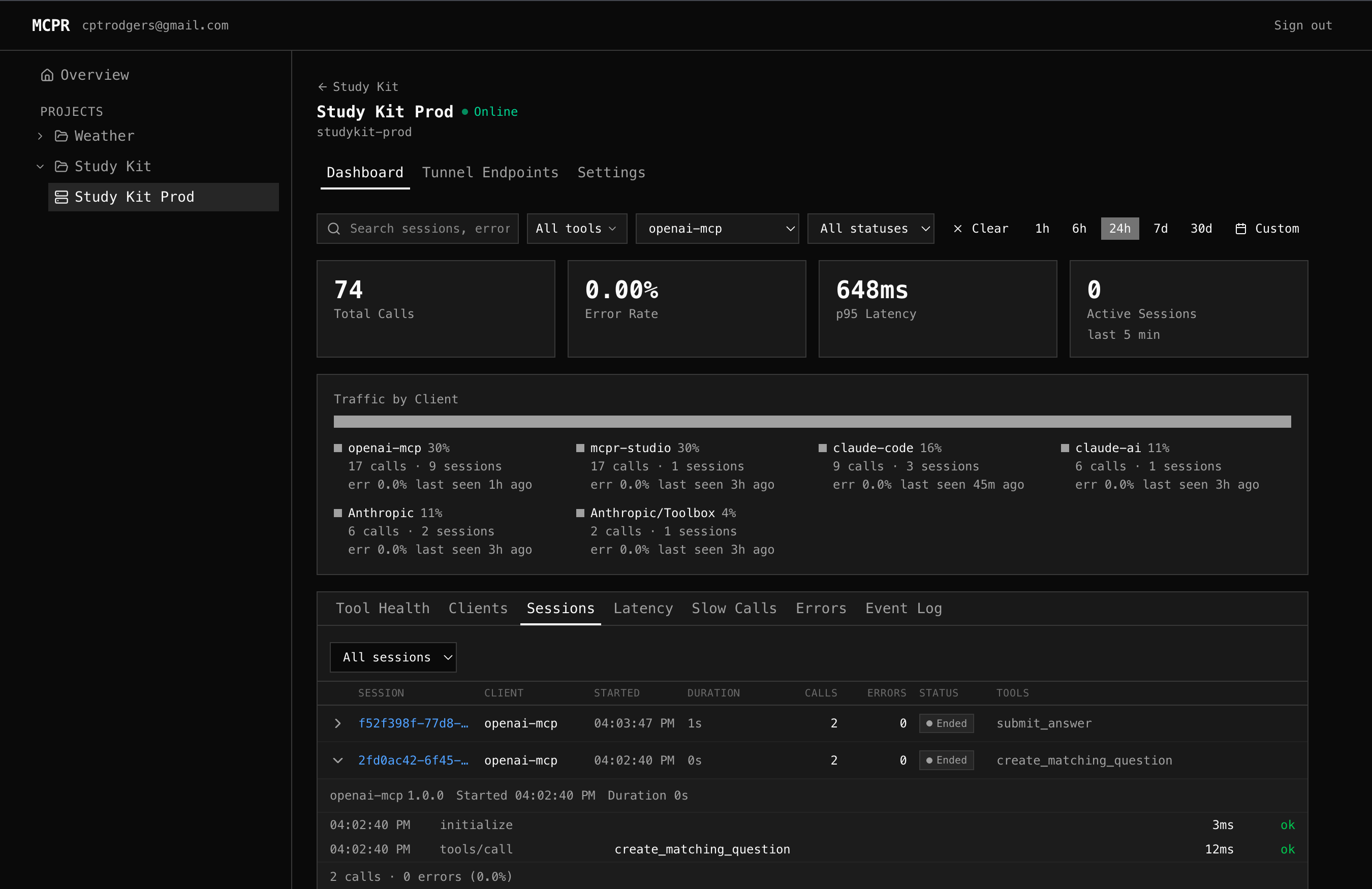
ChatGPT — one session per tool call
Section titled “ChatGPT — one session per tool call”Session 1: 04:02:40 PM initialize 3ms ok 04:02:40 PM tools/call create_matching_question 12ms ok -- session ended --
Session 2: 04:03:47 PM initialize 3ms ok 04:03:47 PM tools/call submit_answer 12ms ok -- session ended --Two sessions. Two full initialize handshakes. Each session lives for roughly one second — just long enough to shake hands, call a tool, and disappear.
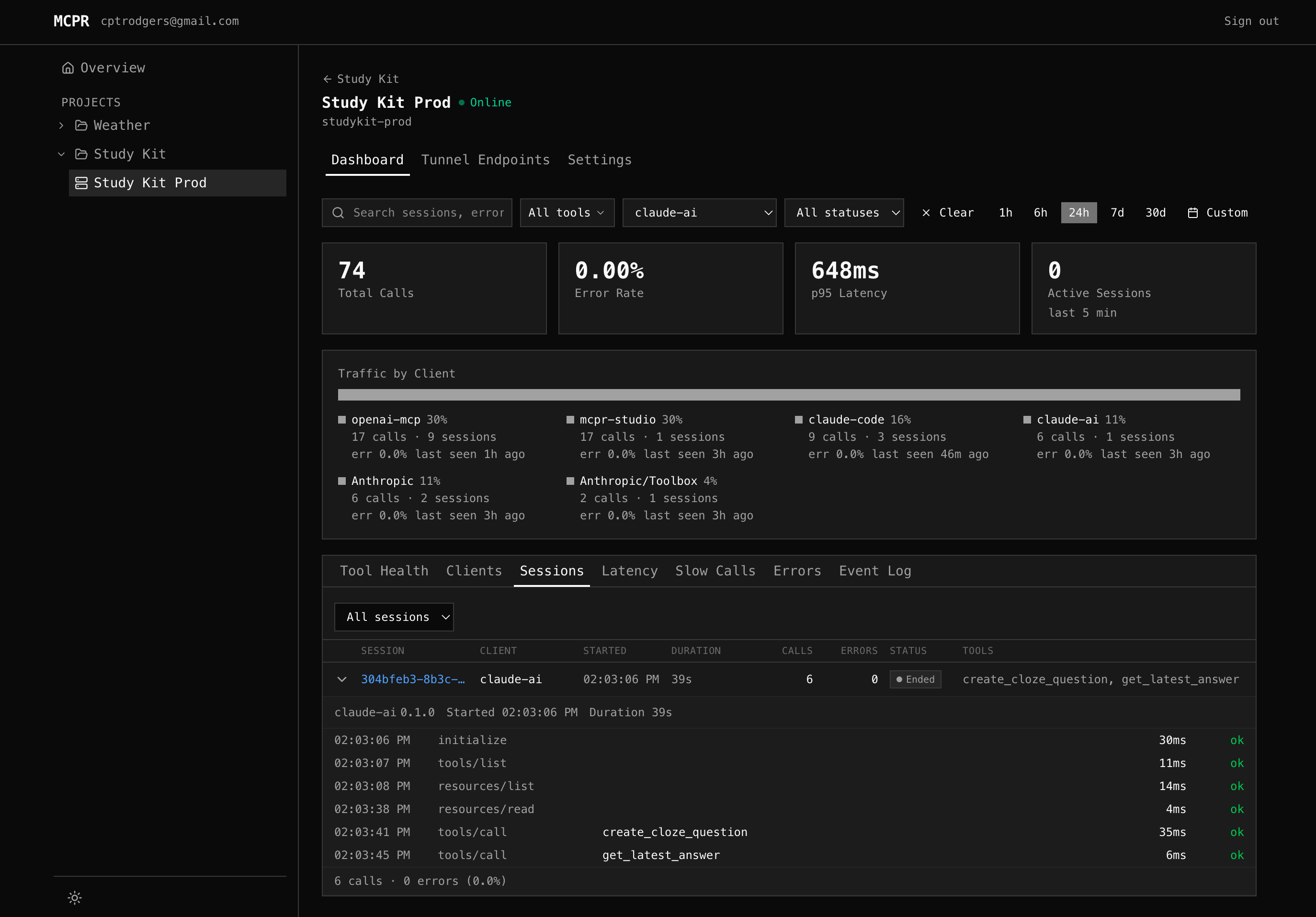
Claude — one session, many calls
Section titled “Claude — one session, many calls”Session 1: 02:03:06 PM initialize 30ms ok 02:03:07 PM tools/list 11ms ok 02:03:08 PM resources/list 14ms ok 02:03:38 PM resources/read 4ms ok 02:03:41 PM tools/call create_cloze_question 35ms ok 02:03:45 PM tools/call get_latest_answer 6ms ok -- session ended --One session. One initialize. Claude even runs discovery — tools/list, resources/list, resources/read — before making any tool calls. All within the same session. Total duration: 39 seconds.
Why this matters more than you think
Section titled “Why this matters more than you think”1. Initialize is not free
Section titled “1. Initialize is not free”Every MCP initialize is a full handshake. The client sends its capabilities, the server responds with its own, they negotiate a protocol version. Some servers also load config, set up database connections, or warm caches during init.
ChatGPT pays this cost on every single tool call. Claude pays it once.
A conversation that triggers 10 tool calls means 10 handshakes on ChatGPT vs 1 on Claude. If your initialize takes 30-50ms — which is modest — you’re adding 300-500ms of pure overhead that your users feel but can’t explain.
And that’s the optimistic case. We’ve seen MCP servers where initialize fetches user preferences, loads database schemas, or warms embedding caches. If your init takes 200ms, ten tool calls just cost you two full seconds of invisible latency on ChatGPT.
2. Your in-memory state is gone
Section titled “2. Your in-memory state is gone”This is the sneaky one. The silent killer.
If your MCP server stores anything in memory per session — user context, conversation history, cached API responses, computed state — ChatGPT will destroy it between tool calls.
# This pattern works perfectly on Claude.# On ChatGPT, it's a landmine.
session_cache = {}
async def handle_initialize(session_id): session_cache[session_id] = {"user": None, "history": []}
async def handle_tool_call(session_id, tool, args): # On Claude: same session_id, cache hit, everything works # On ChatGPT: NEW session_id, cache miss, data is gone cache = session_cache.get(session_id) # None on ChatGPT!You test on Claude. Everything works. State persists across tool calls. You ship it. Then ChatGPT users start reporting bugs — results missing context, follow-up calls returning empty data, conversations that seem to “forget” what just happened.
The worst part? Your server logs show zero errors. Every individual request succeeds. The failure is between requests, in the gap where your state quietly vanishes.
3. Tool discovery follows different paths
Section titled “3. Tool discovery follows different paths”Look at the session data again. Claude calls tools/list and resources/list during the session. It discovers what’s available, reads resources, then acts on what it learned.
ChatGPT skips all of this. It goes straight to initialize then tools/call. No discovery phase. This suggests ChatGPT caches the tool schema externally and doesn’t need to rediscover it per session — which makes sense given the disposable session model.
This is actually clever engineering on ChatGPT’s side: if you’re going to throw away the session anyway, why waste time discovering what you already know?
How to build MCP servers that survive both models
Section titled “How to build MCP servers that survive both models”The rule is simple: design for the worst case.
Make initialize blazing fast
Section titled “Make initialize blazing fast”ChatGPT will call it constantly. Every millisecond in init multiplies across every tool call in a conversation.
# Bad: heavy init that ChatGPT will pay for on every tool callasync def handle_initialize(session_id): await load_database_schema() # 200ms await warm_embedding_cache() # 500ms await fetch_user_preferences() # 100ms # Total: 800ms per tool call on ChatGPT
# Good: return immediately, defer everythingasync def handle_initialize(session_id): return {"capabilities": {...}} # < 5msGo stateless or go home
Section titled “Go stateless or go home”Don’t rely on session-scoped state. Period. Use external persistence keyed on something stable — user ID, API key, anything that survives a session reset.
# Fragile: dies on ChatGPTsession_state = {}
# Robust: works everywhereasync def get_state(user_id): return await redis.get(f"user:{user_id}")Pass context explicitly
Section titled “Pass context explicitly”If tool B depends on output from tool A, don’t cache it in session memory. Return it as structured output so the AI client can pass it back as input. Let the AI be the state carrier — it’s the only thing that actually persists across ChatGPT’s disposable sessions.
How we spotted this
Section titled “How we spotted this”A regular HTTP reverse proxy — nginx, HAProxy, Caddy — would see these as normal HTTP requests. It has no idea that two POST requests belong to different MCP sessions, or that initialize was called twice instead of once.
mcpr is different. It parses MCP JSON-RPC at the protocol level. It knows what initialize means, tracks session IDs, groups tool calls by session, and measures per-method latency. That’s how a pattern like this surfaces in the dashboard instead of hiding in raw HTTP logs.
If you’re running MCP servers in production, this kind of protocol-level visibility is the difference between guessing why things are slow and knowing.
The takeaway
Section titled “The takeaway”ChatGPT and Claude have fundamentally different MCP session models:
| ChatGPT | Claude | |
|---|---|---|
| Session lifetime | One tool call | Entire conversation turn |
| Initialize calls | Once per tool call | Once per session |
| In-memory state | Lost between calls | Persists within session |
| Tool discovery | Skipped (cached externally) | Done within session |
Design for the disposable model. If your server works on ChatGPT’s session-per-call approach, it’ll work everywhere. The reverse is not true.
mcpr is an open-source MCP proxy (Apache 2.0). See session data like this in the cloud dashboard at cloud.mcpr.app.